Spark基本工作原理与RDD
一、spark基本的原理
1、分布式
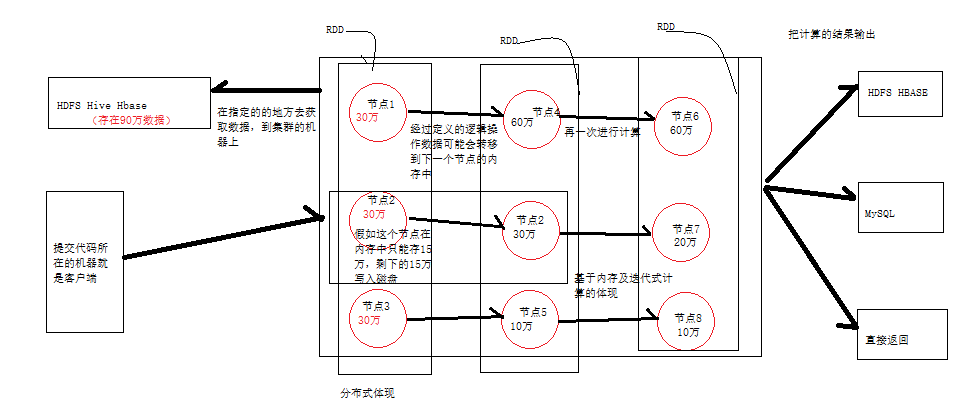
所谓的分布式就客户端在提交spark程序之后,spark会根据程序所指的的目录去读取数据,在这里读取数据的方式有三种HDFS、本地文件系统以及集合,在读取数据之后会把 数据分布到不同的节点上,例如现在有90万条数据,存在三个节点那么每个节点上面就会有30万数据。
2、基于内存
在读取来的数据默认是存放在内存当中,当内存的容量不够才会把数据写到磁盘中去,但是这一切对于用户来说都是透明的,用户不用去管何时该把数据写入内存。
3、迭代式计算
在数据都读取到内存之后回去执行spark程序所指定的计算操作,这些计算都是内存式迭代计算可以有n多个阶段
4、补充:spark与MR的区别如下:
(1)、MR只有map与reduce两个阶段,当这两个阶段完了之后计算也就完成了所以处理能力有限,但是Spark有N多个阶段处理的能力相对于MR有所提高
(2)spark是基于内存的,而MR在运算的过程中要经过磁盘所以速度相对于spark慢
5、说了这么多直接上图

二、RDD
1、RDD即分布式弹性数据集
2、所谓分布式就是读去的数据分为不同的分区,这些分区散落在集群的不同节点上这就是分布式的体现
3、所谓数据集就是多个分区的数据构成了RDD这个集合
4、所谓弹性就是指在分区的内存没有足够的容量来存放数据时候数据会被写入磁盘
5、容错性,在某个分区因为各种原因造成数据的损坏和丢失,这时spark不会脆弱到直接报错而是从数据的来源重新计算一次得到到原来的数据
6、RDD的示意图

spark计算过程主要是RDD的迭代计算过程
三、综合spark的原理RDD如下图所示: